时间: 2026年4月11日(周六) 9: 00
地点: 望江校区基础教学楼B座318实验室
分享者: 魏楷臻、周寅杰
Part 1
分享者: 魏楷臻
分享内容:
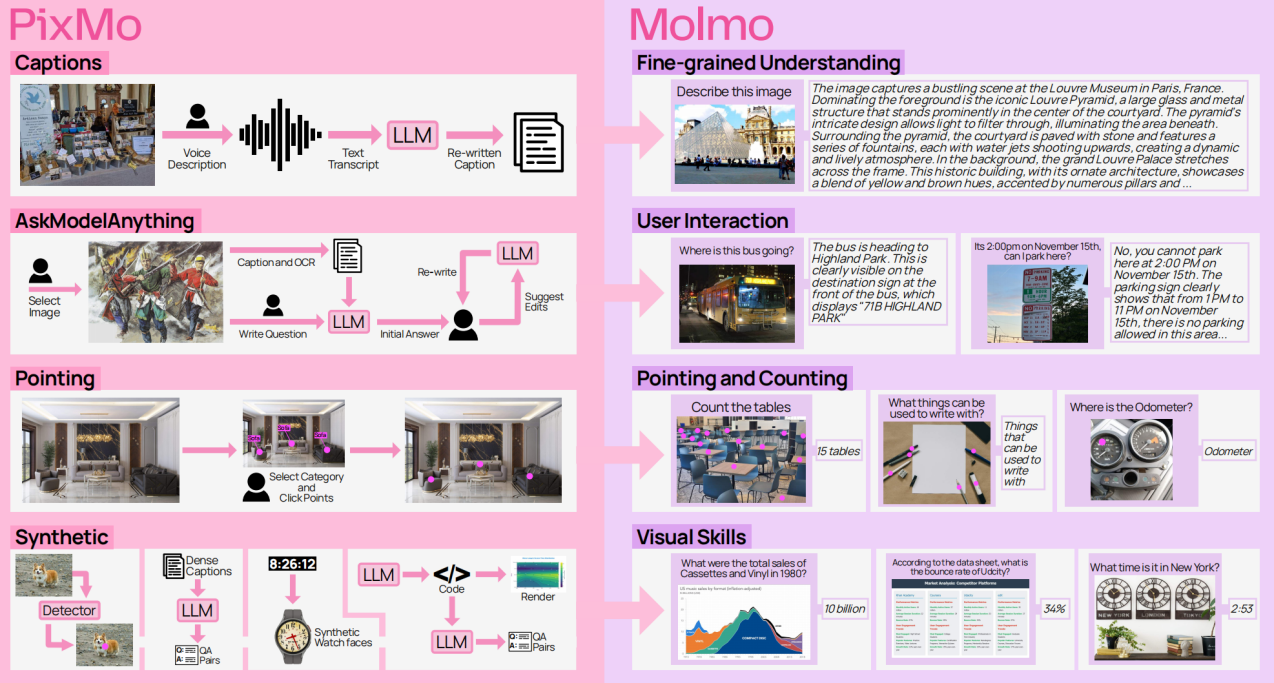
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, and et al. Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 91-104.
论文简介:
如今最先进的视觉语言模型(Vision-Language Model, VLM)仍然是闭源的,而一些性能优秀的开源模型也严重依赖这些闭源VLM所提供的合成数据,这些开源模型本质上是对闭源模型的“蒸馏”。一直以来,开源社区都缺少了一个基础知识:如何从头开始构建高性能的视觉语言模型? Molmo则是一个全新的VLM系列,其主要贡献之一是收集了数据集PixMo(PixMo的数据收集不依赖额外的大模型)。Molmo&PixMo详细介绍了多模态大模型的数据采集、模型设计、训练以及评估。Molomo系列里面最好的72B大模型不仅在开源大模型方面优于其他大模型,而且在基准测试和人类评估上也超过了更大的闭源大模型,包括 Claude 3.5 Sonnet、Gemini 1.5 Pro,仅次于GPT-4o。
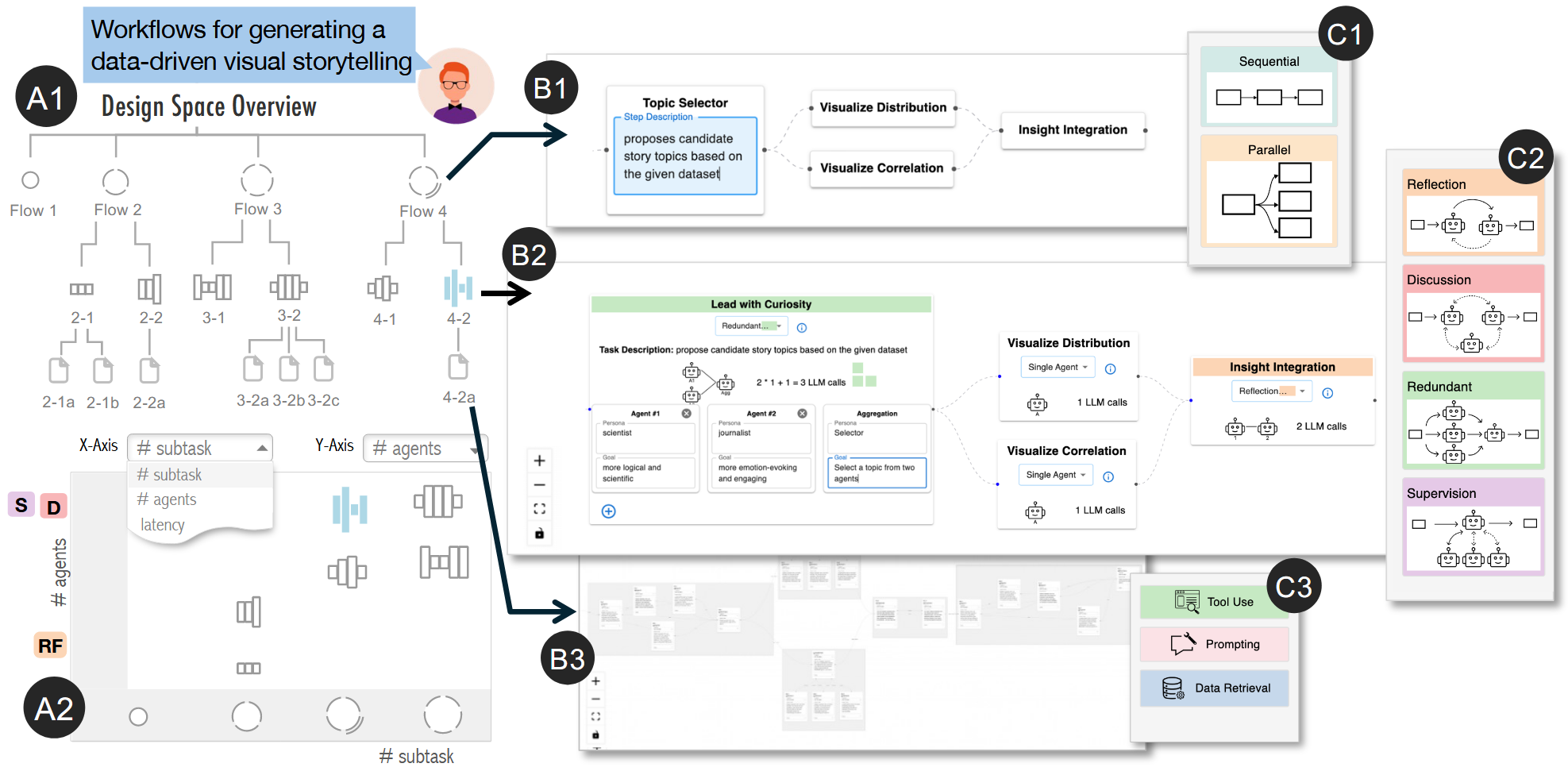
Part 2
分享者: 周寅杰
分享内容:
Hao, P., Kang, D., Hinds, N., & Wang, Q. (2025). FlowForge: Guiding the creation of multi-agent workflows with design space visualization as a thinking scaffold. IEEE Transactions on Visualization and Computer Graphics.
论文简介:
多智能体工作流通过将复杂任务分解为多个子任务并分配给专业化智能体执行,已成为处理复杂问题的有效策略。然而,由于设计空间广阔且错综复杂,如何构建最优工作流仍是一项挑战。当前实践严重依赖从业者的直觉与经验,往往导致设计固化或陷入耗时且缺乏系统性的试错式探索。为应对这些挑战,本研究推出FLOWFORGE——一款交互式可视化工具,旨在通过以下方式辅助多智能体工作流的创建:一)对设计空间进行结构化视觉探索;二)基于成熟设计模式提供原位情境引导。基于形成性研究与文献综述,FLOWFORGE将工作流设计过程组织为从抽象到具体的三个层级(即任务规划、智能体分配与智能体优化)。这种结构化视觉探索机制使用户能够从高层规划无缝过渡至具体设计决策与实现环节,同时可依据多维性能指标比较备选方案。此外,借鉴经典工作流设计模式,FLOWFORGE在用户遍历设计空间时,会在各层级提供上下文感知的原位建议,通过实用性指导提升工作流创建体验。应用案例与用户研究证实了FLOWFORGE的可用性与有效性,同时揭示了从业者在工作流开发过程中探索设计空间及运用辅助引导机制的深层规律。