时间:2026年3月21日(周六) 9: 00
地点:望江校区基础教学楼B座318实验室
分享者:刘宜松、杨阳
Part 1
分享者:刘宜松
分享内容:
Gu X, Shen Y, Luo C, et al. Knowing your target: Target-aware transformer makes better spatio-temporal video grounding[J]. arXiv preprint arXiv:2502.11168, 2025. ICLR(Oral)
论文简介:
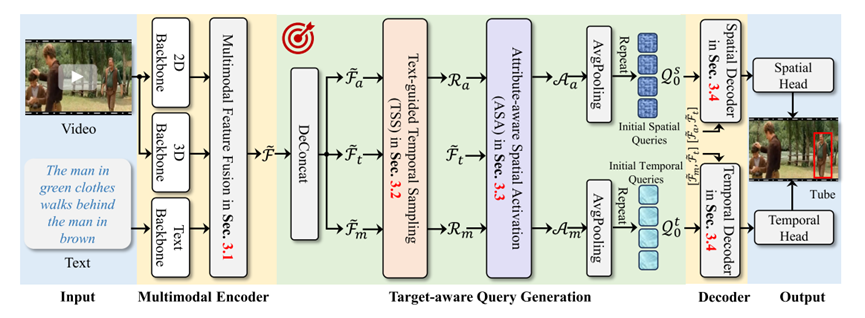
近年来,随着 Transformer 架构在视觉与语言领域的广泛应用,基于其端到端建模能力和优越性能,时空视频接地(STVG)任务逐渐成为研究热点。STVG旨在根据自然语言描述,在视频中精确定位目标的时空范围,是多模态理解的重要方向之一。现有基于Transformer的STVG方法通常依赖一组对象查询(Object Queries)来进行目标定位。这些查询往往采用零初始化,并通过与视频和文本的多模态特征进行多轮交互,逐步学习目标信息。尽管该策略实现简单,但由于缺乏明确的目标先验,这类方法在复杂场景(如遮挡、干扰或背景混杂)下,往往难以有效区分目标与非目标区域,导致性能下降。针对这一问题,这篇文章提出了一种目标感知的时空视频接地模型——TA-STVG(Target-Aware Transformer for STVG)。该方法的核心思想是:不再使用无信息的初始查询,而是直接从视频-文本对中挖掘目标相关线索,自适应生成对象查询,从而提升模型的判别能力。具体而言,TA-STVG包含两个关键模块:文本引导的时间采样(TTS):利用整体文本语义,从视频中筛选出与目标最相关的关键时间片段;属性感知的空间激活(ASA):在已筛选的时间线索基础上,进一步挖掘目标的细粒度视觉属性信息,用于指导对象查询的初始化。这两个模块级联工作,使生成的对象查询天然携带目标相关信息,从而能够更有效地与多模态特征进行交互,学习更具区分性的表示。在多个主流基准数据集(如HCSTVG-v1、HCSTVG-v2和VidSTG)上的实验结果表明,TA-STVG显著优于现有方法,达到了新的性能水平。此外,所提出的TTS和ASA模块具有良好的通用性,在集成到现有方法(如 TubeDETR 和 STCAT)中时,同样带来了稳定且显著的性能提升。本工作为STVG任务提供了一种新的思路:通过显式引入目标感知机制,打破传统零初始化查询的限制,为复杂场景下的多模态理解提供了更具鲁棒性的解决方案。
Part 2
分享者:杨阳
分享内容:
Zhang, Fan, Zhiwei Gu, and Hua Wang. "Decoding with structured awareness: integrating directional, frequency-spatial, and structural attention for medical image segmentation." arXiv preprint arXiv:2512.05494 (2025).
论文简介:
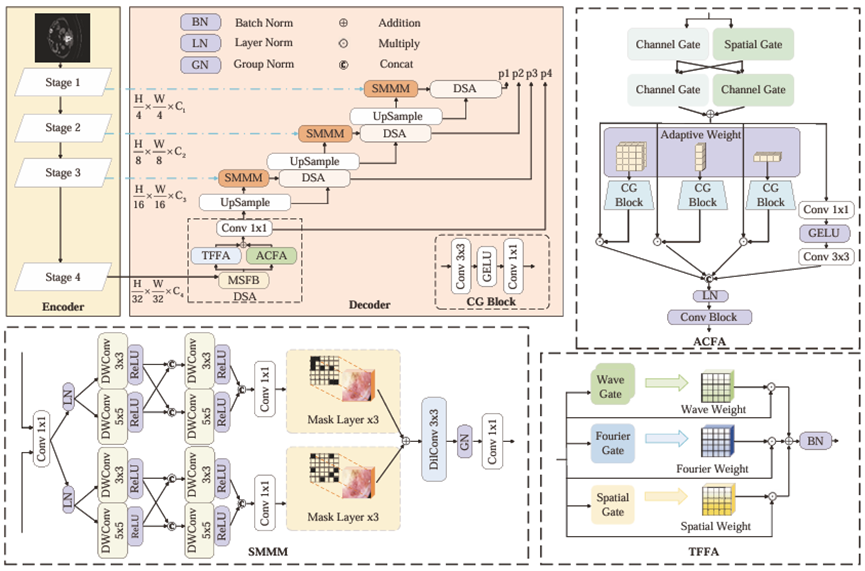
为了解决Transformer 解码器在捕获边缘细节、识别局部纹理以及建模空间连续性方面的局限,本文提出了一种面向医学图像分割的全新解码器框架,由三个核心模块组成。首先,自适应交叉融合注意力(Adaptive Cross-Fusion Attention,ACFA)模块将通道特征增强与空间注意机制相结合,并引入三个方向(平面、水平与垂直)的可学习引导,以增强模型对关键区域与结构方向的响应能力。其次,三重特征融合注意力(Triple Feature Fusion Attention,TFFA)模块融合空间域、傅里叶域与小波域特征,实现频率-空间的联合表征,从而在保留边缘与纹理等局部信息的同时,加强全局依赖与结构建模,尤其适用于结构复杂与边界模糊的场景。最后,结构感知多尺度掩蔽模块(Structural-aware Multi-scale Masking Module,SMMM)通过利用多尺度上下文与结构显著性过滤来优化编码器与解码器之间的跳跃连接,有效减少特征冗余并提升语义交互质量。三者协同工作,不仅弥补传统解码器的不足,还能显著提升肿瘤分割、器官边界提取等高精度任务的表现,提高分割精度与模型泛化能力。实验结果表明,该框架为医学图像分割提供了一种高效且实用的解决方案。