时间:2026年05月16日(周六)上午09:00
地点:望江校区基础教学楼B座318实验室
分享者:卢玉杰、甘小容、周寅杰
Part1
分享者:卢玉杰
分享内容:
[1]Tian K, Jiang Y, Yuan Z, et al. Visual autoregressive modeling: Scalable image generation via next-scale prediction[J]. Advances in neural information processing systems, 2024, 37: 84839-84865.
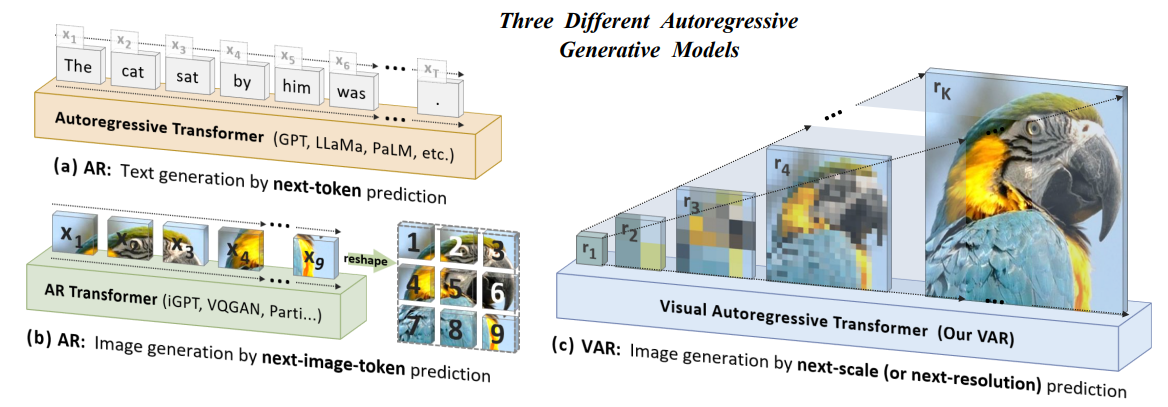
提出了视觉自回归建模(VAR),这是一种全新的生成范式,它将图像上的自回归学习重新定义为从粗到细的“下一尺度预测”或“下一分辨率预测”,与标准的栅格扫描式“下一标记预测”不同。这一简单直观的方法使得自回归(AR)Transformer能够快速学习视觉分布并具有很好的泛化能力:VAR首次使得GPT风格的自回归模型在图像生成上超越扩散Transformer。在ImageNet 256×256基准测试中,VAR显著改进了AR基线,将弗雷歇初始距离(FID)从18.65提升到1.73,初始分数(IS)从80.4提升到350.2,同时推理速度提高了20倍。实验还证明,VAR在图像质量、推理速度、数据效率和可扩展性等多个维度上均优于扩散Transformer(DiT)。VAR模型的扩展表现出与大型语言模型(LLM)中观察到的相似的清晰幂律缩放规律,线性相关系数接近-0.998,这是有力的证据。此外,VAR在图像修复、外推绘制和编辑等下游任务中展现了零样本泛化能力。这些结果表明VAR初步模仿了LLM的两个重要特性:缩放定律和零样本泛化。
Part2
分享者:甘小容
分享内容:
[2]Xie S, Zhang L, Niu Z, et al. EICSeg: Universal Medical Image Segmentation via Explicit In-Context Learning[J]. IEEE Transactions on Medical Imaging, 2025.
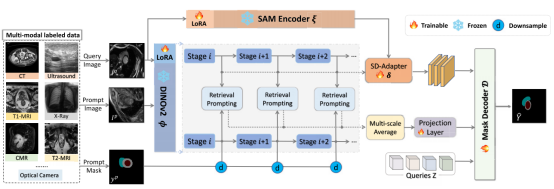
以往医学图像分割方法通常针对特定任务专门训练模型,面对新器官、新模态或新标签时泛化能力有限,往往需要重新训练或微调。现有少样本以及上下文分割方法虽然尝试利用少样本完成新任务分割,但多数依赖隐式学习查询图像和支持集之间的关系,容易丢失细粒度空间信息,并且在多类别医学分割场景中仍存在效率和准确性不足的问题。针对上述问题,本文提出EICSeg,一种面向通用医学图像分割的显式上下文学习框架,将查询图像与带标注提示图像之间的交互重新建模为patch级别的显式检索过程,从而实现多类别标签信息的高效传播。该方法采用DINOv2和SAM作为编码器,进一步结合了DINOv2的语义对应能力与SAM的空间细节表达,并设计轻量级SD-Adapter进行特征融合,以增强目标区域、抑制无关背景,提升复杂解剖结构的分割质量。在面对新任务是,无需额外训练。EICSeg在多个未见过的医学图像分割数据集上取得了优于现有 few-shot和in-context segmentation方法的泛化性能,并展现出较强的少样本适应能力,为低标注成本、跨模态、跨任务的医学图像自动分割提供了新的思路。
Part3
分享者:周寅杰
分享内容:
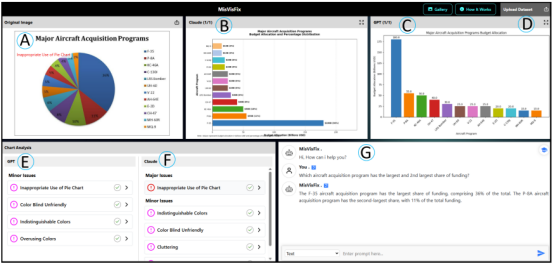
[3]Das A K, Mueller K. Misvisfix: An interactive dashboard for detecting, explaining, and correcting misleading visualizations using large language models[J]. IEEE Transactions on Visualization and Computer Graphics, 2025.
误导性可视化对准确的数据解读构成了严峻挑战。尽管大型语言模型(LLMs)已在可视化中的错误信息检测方面得到研究,但能够提供解释与修正的实用工具仍然匮乏。为此,我们提出了 MisVisFix——一个利用 Claude 和 GPT双模型的交互式仪表板,支持对误导性可视化进行检测、解释和修正的完整工作流。该系统能正确识别 96% 的可视化问题,覆盖全部74种已知的可视化误导类型,并将其按严重程度分类为严重(major)、轻微(minor)和潜在(potential)问题。系统提供详细的解释、改进建议以及自动生成的修正图表,并配备交互式对话界面,允许用户就特定图表元素进行提问或请求修改。通过针对性的用户交互,系统能够适应新出现的误导策略。与可视化专家和事实核查工具开发者开展的用户研究证实了该系统的准确性和实用性。MisVisFix旨在提升可视化素养,推动更可信的数据传播。